简介 本文主要讲解如何使用helm3在gke上安装prometheus-operator,包含持久化存储的使用。
今天会先最简单安装一下prometheus-operator,然后再一步一步优化,最终我们使用自定义Chart文件保存为私有的安装包。
前提
安装并会使用helm3
步骤
安装helm3
最简安装prometheus-operator
使用ingress来暴露服务
创建自定义chart文件
① 设置自定义ns
② 设置svc暴露方式为NodePort
③ 自定义ingress
④ 设置持久化存储
⑤ 自定义镜像
⑥ 修改默认grafana的用户密码
⑦ 打包
开始 1. 安装helm3 非常简单,官方文档给出了几种安装方式,随便一个都行。文档
这里我采用最简单的二进制文件安装即可
1 2 3 4 1.到这里下载适合你系统的二进制文件包https://github.com/helm/helm/releases 2.tar -zxvf helm-v3.0.0-linux-amd64.tar.gz 3.mv linux-amd64/helm /usr/local/bin/helm 4.helm help 验证下是否安装成功
安装好之后,我们配置下helm的仓库,既然安装prometheus-operator,那么就先add一个他的仓库。
1 2 3 4 5 1.helm repo add stable https://charts.helm.sh/stable 2.验证仓库,helm repo list [root@localhost]# helm repo list NAME URL stable https://charts.helm.sh/stable
最简安装prometheus-operator
如果你不知道prometheus-operator是什么,以及他包含了啥,请移步这里:文档
1.查找一下我们仓库中的prometheus-operator的包
1 2 3 [root@localhost]# helm search repo prometheus-operator NAME CHART VERSION APP VERSION DESCRIPTION stable/prometheus-operator 9.3.2 0.38.1 DEPRECATED Provides easy monitoring definitions...
2.直接安装,报错暂时忽略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@localhost]# helm install <release-name> --namespace <your-namespace> stable/prometheus-operator WARNING: This chart is deprecated manifest_sorter.go:192: info: skipping unknown hook: "crd-install" manifest_sorter.go:192: info: skipping unknown hook: "crd-install" manifest_sorter.go:192: info: skipping unknown hook: "crd-install" manifest_sorter.go:192: info: skipping unknown hook: "crd-install" manifest_sorter.go:192: info: skipping unknown hook: "crd-install" manifest_sorter.go:192: info: skipping unknown hook: "crd-install" NAME: eve-prometheus-operator LAST DEPLOYED: Fri Nov 6 13:50:46 2020 NAMESPACE: meitu-monitoring STATUS: deployed REVISION: 1 NOTES: ******************* *** DEPRECATED **** ******************* * stable/prometheus-operator chart is deprecated. * Further development has moved to https://github.com/prometheus-community/helm-charts * The chart has been renamed kube-prometheus-stack to more clearly reflect * that it installs the `kube-prometheus` project stack, within which Prometheus * Operator is only one component. The Prometheus Operator has been installed. Check its status by running: kubectl --namespace meitu-monitoring get pods -l "release=eve-prometheus-operator" Visit https://github.com/coreos/prometheus-operator for instructions on how
3.安装完成之后,你就可以在你的ns下看到资源了
1 2 3 4 5 6 7 8 9 [root@beautyplus-bigdata-gcp pre]# kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-prometheus-operator-alertmanager-0 2/2 Running 0 53m prometheus-operator-grafana-b4494db55-f87mt 2/2 Running 0 53m prometheus-operator-kube-state-metrics-5fd49d67d-xhpjs 1/1 Running 0 53m prometheus-operator-operator-75d86956bb-4rg99 2/2 Running 0 53m prometheus-operator-prometheus-node-exporter-hvccz 1/1 Running 0 53m prometheus-operator-prometheus-node-exporter-l4kdx 1/1 Running 0 53m prometheus-prometheus-operator-prometheus-0 3/3 Running 0 53m
3.使用ingress来暴露服务 注意:我们首先看下安装好之后的svc信息
1 2 3 4 5 6 7 8 9 10 [root@localhost]# kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 56m prometheus-operator-alertmanager ClusterIP 10.220.0.220 <none> 9093:31261/TCP 57m prometheus-operator-grafana ClusterIP 10.220.0.54 <none> 80:30830/TCP 57m prometheus-operator-kube-state-metrics ClusterIP 10.220.0.249 <none> 8080/TCP 57m prometheus-operator-operator ClusterIP 10.220.0.178 <none> 8080/TCP,443/TCP 57m prometheus-operator-prometheus ClusterIP 10.220.0.55 <none> 9090:32218/TCP 57m prometheus-operator-prometheus-node-exporter ClusterIP 10.220.0.253 <none> 9100/TCP 57m prometheus-operated ClusterIP None <none> 9090/TCP 56m
正常来讲都是ClusterIP的方式,如果我们没有公网代理等,请直接修改ClusterIP为NodePort方式。如果你有公网代理等,直接不用修改,创建ingress资源即可。
不过,gke特殊,如果你想暴露你的服务,必须要求你的svc是NodePort方式或者是LoadBalancer方式,所以在gke上使用ingress方式来暴露服务,那么必须要先修改svc为NodePort方式
1 2 3 [root@localhost]# kubectl edit svc prometheus-operator-alertmanager -n monitoring [root@localhost]# kubectl edit svc prometheus-operator-grafana -n monitoring [root@localhost]# kubectl edit svc prometheus-operator-prometheus -n monitoring
修改完上述内容,那么我们直接创建ingress资源:(注意需要提前创建下secret证书)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@localhost]# cat ingress.yaml apiVersion: extensions/v1beta1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/enable-cors: "true" name: prometheus-ingress namespace: monitoring spec: rules: - host: grafana.xx.com http: paths: - backend: serviceName: prometheus-operator-grafana servicePort: 80 - host: prometheus.xx.com http: paths: - backend: serviceName: prometheus-operator-prometheus servicePort: 9090 - host: alertmanager.xx.com http: paths: - backend: serviceName: prometheus-operator-alertmanager servicePort: 9093 tls: - secretName: x-xx-com-20201106
创建完直接apply一下,应用即可:
1 [root@localhost]# kubectl apply -f ingress.yaml
最后到gcp控制台观察下该ingress创建的状态,拿到公网ip,本地绑定host测试下就行。
注意:grafana默认的用户密码是admin/prom-operator
4. 创建自定义chart文件 首先我们下载chart文件
1 2 3 [root@localhost]# helm pull stable/prometheus-operator [root@localhost]# tar xzvf prometheus-operator-9.3.2.tgz [root@localhost]# cd prometheus-operator/
① 设置自定义ns 1 修改values.yaml中的namespaceOverride字段,设置为自己的ns
② 设置svc暴露方式为NodePort 1 2 3 4 5 6 7 1.修改alertmanager.service.type为NodePort 2.修改prometheus.service.type为NodePort 3.grafana比较特殊,需要在charts/grafana/values.yaml文件中的service下添加以下内容: service: type: NodePort port: 3000 targetPort: 3000
③ 自定义ingress 这个不建议了,因为这样默认会创建出三个公网ip,比较麻烦,最好的方式是安装好之后,单独定义一个ingress资源,去代理这三个服务:alertmanager、grafana、prometheus。
具体方法看上面说的ingress服务暴露。(注意:你前面已经吧grafana的暴露方式修改成NodePort,并且把端口也改了,注意修改ingress文件)
④ 设置持久化存储(prometheus+grafana) 首先你需要了解pv,pvc,StorageClass三个概念,不然没法进行下去。
注意:其实正常来讲你不用手动创建一个sc的,因为而且在gke提供了一个默认的standard (default) ,而且在gke上,我们是直接创建pvc,不用创建pv的,因为gke的csi已经帮我们管理pv了,即云厂商的磁盘服务而已。
【prometheus持久化存储】
当我们使用helm来设置自定义存储的时候,我们只需要:
1.创建一个sc
2.并且修改values文件的配置,不用再创建pvc了。
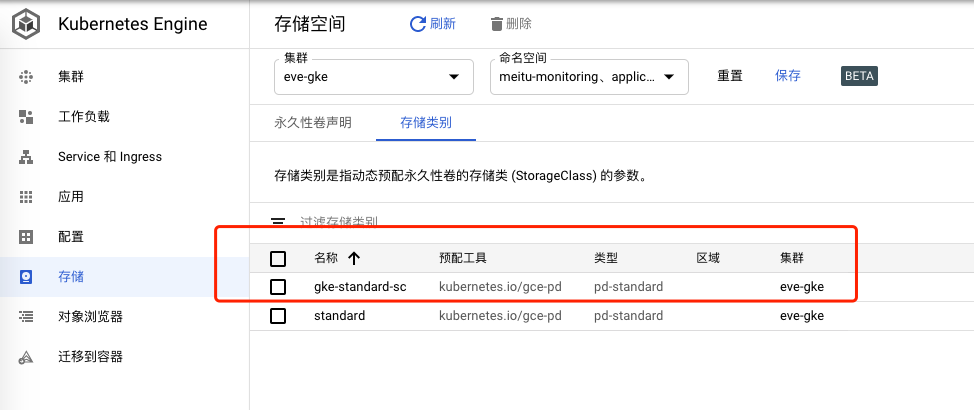
1 2 3 4 5 6 7 8 9 10 11 12 [root@localhost]# cat sc.yaml kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: gke-standard-sc namespace: monitoring provisioner: kubernetes.io/gce-pd parameters: type: pd-standard volumeBindingMode: WaitForFirstConsumer # pvc创建后不会创建pv,只有pod正常后才会创建pv,也就是具体存储 reclaimPolicy: Retain # 回收策略,pvc删除后,数据不会删除 [root@localhost]# kubectl apply -f sc.yaml
创建好sc就可以在gcp看到如下内容:
1 2 3 4 5 6 7 8 9 [root@localhost]# vim values.yaml(注意是prometheus.prometheusSpec) storageSpec: volumeClaimTemplate: spec: storageClassName: gke-standard-sc accessModes: ["ReadWriteOnce"] resources: requests: storage: 50Gi
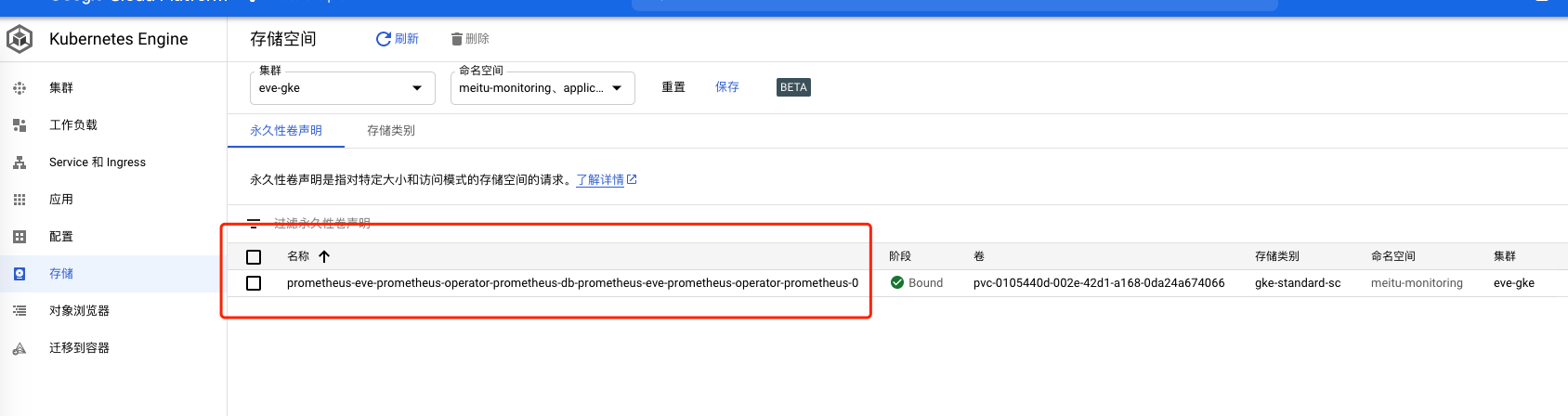
修改完上述内容,然后安装好prometheus后,就能看到新的pvc创建出来了。
【grafana持久化存储】
首先也是要使用上面创建的sc,并自已创建pvc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@localhost]# cat grafana-pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gke-grafana-pvc namespace: meitu-monitoring spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: gke-standard-sc [root@localhost]# kubectl apply -f grafana-pvc.yaml
然后修改charts/grafana/values.yaml,使用上面的pvc
1 2 3 4 5 6 7 8 9 10 11 12 persistence: type: pvc enabled: true storageClassName: gke-standard-sc accessModes: - ReadWriteOnce size: 10Gi # annotations: {} finalizers: - kubernetes.io/pvc-protection # subPath: "" existingClaim: gke-grafana-pvc
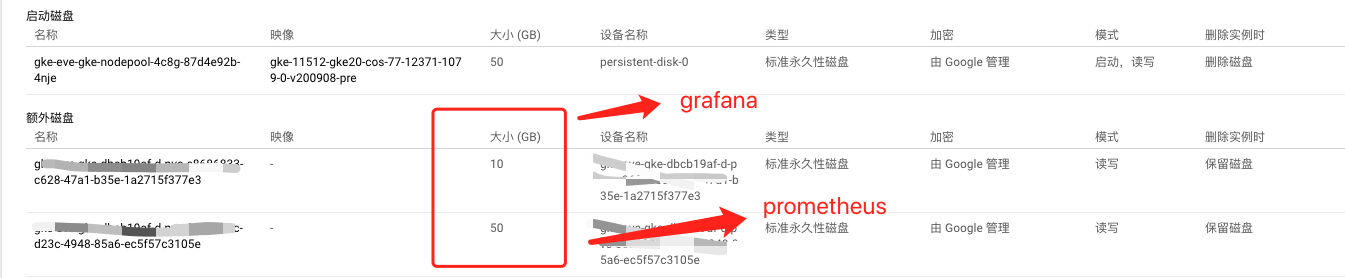
持久化存储搞定之后,我们可以看看我们的grafana和prometheus运行在哪台机器上,然后登录到机器,就可以看到这台机器挂载了你的存储磁盘。
⑤ 自定义镜像 这里只需要注意,你的镜像如果是私有的,那么请设置全局的global.imagePullSecrets
⑥ 修改grafana默认用户密码 注意要注释掉默认values中的grafana.adminPassword配置
1 2 3 [root@localhost]# vim charts/grafana/values.yaml adminUser: abc adminPassword: def
⑦ 打包 1 2 1. 修改Chart.yaml中的name字段,设置为自己的name 2. helm package self-define-name --debug
我们的helm仓库一般使用chartmuseum,如果想看怎么安装或者推送私有镜像到chartmuseum,请看我之前的博客:chartmuseum